UI in AI
Launching in about 2 weeks.
In my last post, I wrote about Hobbes' text chat and why natural language is the fastest way to log a meal, and how we handle the messy shorthand of real people ("same as yesterday," "leftovers," "my usual"). That post was about one of three inputs. This one is about the other two: voice and images.
My intention with Hobbes is to build the world's best health coach. A coach should be available and responsive however you want to reach out: typing, talking, or showing. But each one forced me to rethink the UI.
Voice
The obvious way to build voice logging is to transcribe speech to text and then process it as a text conversation. That's what we built first. It worked, but it felt flat. And every modern phone keyboard already has a mic button that you can dictate into, so this wasn't additive.
I wanted voice to feel different. So we built a dedicated voice UI that does something specific: as you speak, food cards pop up showing what it just heard.
This sounds small, but it changes the interaction. If you list off several items and one gets heard wrong, you see it immediately. You can fix it with your voice ("not 1 cup, I had half a cup"), without restarting the whole dictation or digging into edit menus.
Log meals with voice
The UI really clicks when you say something like "I had the same breakfast as yesterday" or "I had my usual protein drink." The cards populate with the exact items from yesterday, and now you can edit those too. "I had non-fat Greek yogurt instead of regular." It goes from passive dictation to something faster, more accurate, and dare I say, fun.
Log yesterday's lunch
Image
Image logging is the mode I use most often, and it's the hardest for models. Portion sizes are the obvious failure mode. The subtler one is ambiguity: a white grain in a bowl, a brown protein on a plate. All models guess and often get it wrong.
Hobbes knows what you actually eat. The meals you log shape what it sees. If you eat steel-cut oats every morning, an ambiguous bowl of white grain resolves toward oats, not rice. If you eat breakfast at 8, a 7:50 am photo gets tagged breakfast. It knows your dietary preferences too, so it won't confuse tofu with chicken if you're vegetarian.
It also picks up on packaging and labels. A yogurt cup is single-serve, a yogurt tub is not, so it logs the visible portion rather than assuming you ate the whole container. When there's a readable nutrition label in the frame, it pulls the numbers directly from the label rather than estimating.
Then there's the UI, which we borrowed from the voice interface. Instead of confidently stating "you ate X, Y, Z" and logging it, we show cards for each item we think we see. Changing a quantity, removing an item, or fixing a name is one tap. Every correction feeds back into what Hobbes remembers and the next photo gets a little smarter because of the last one.
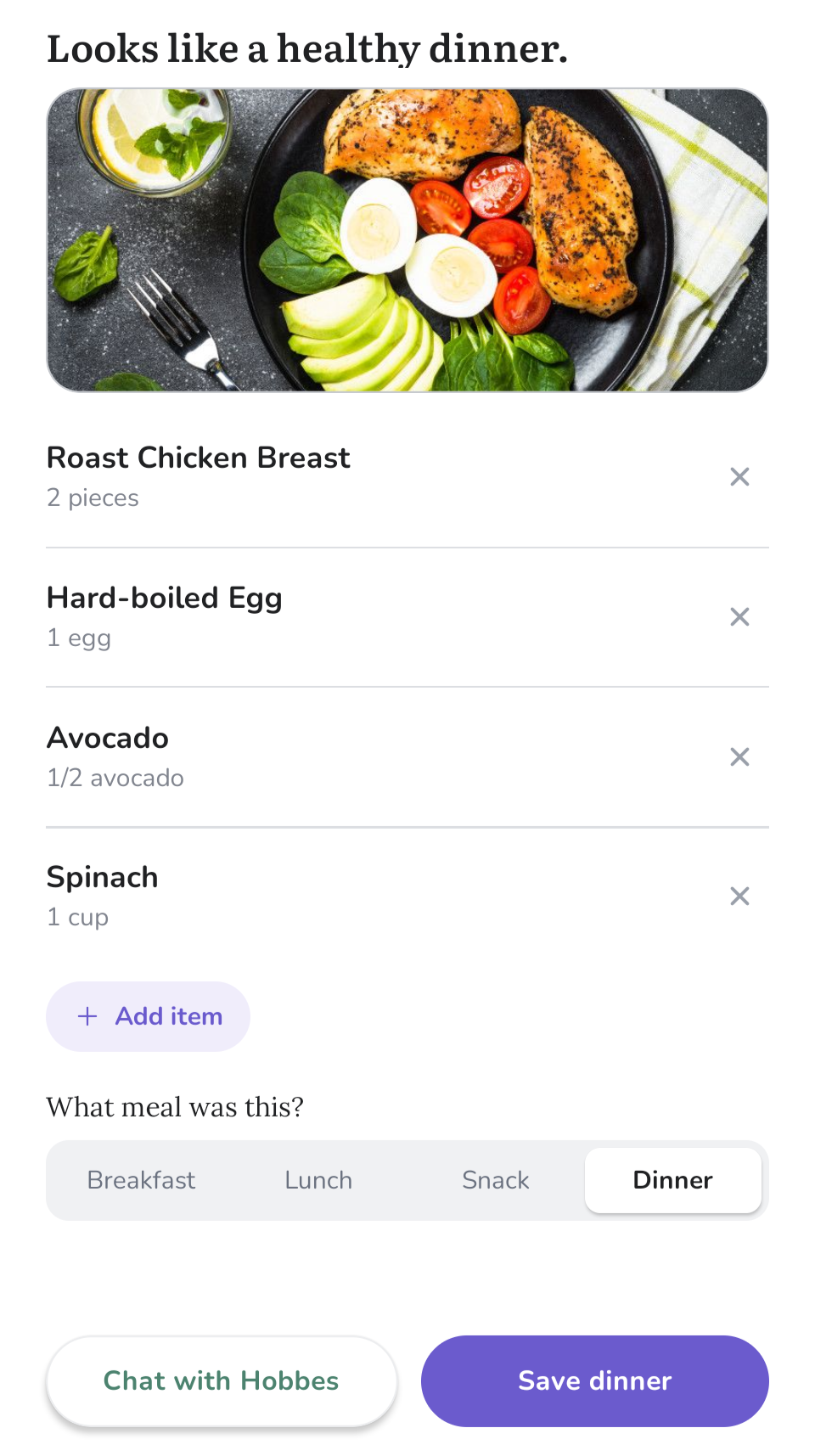
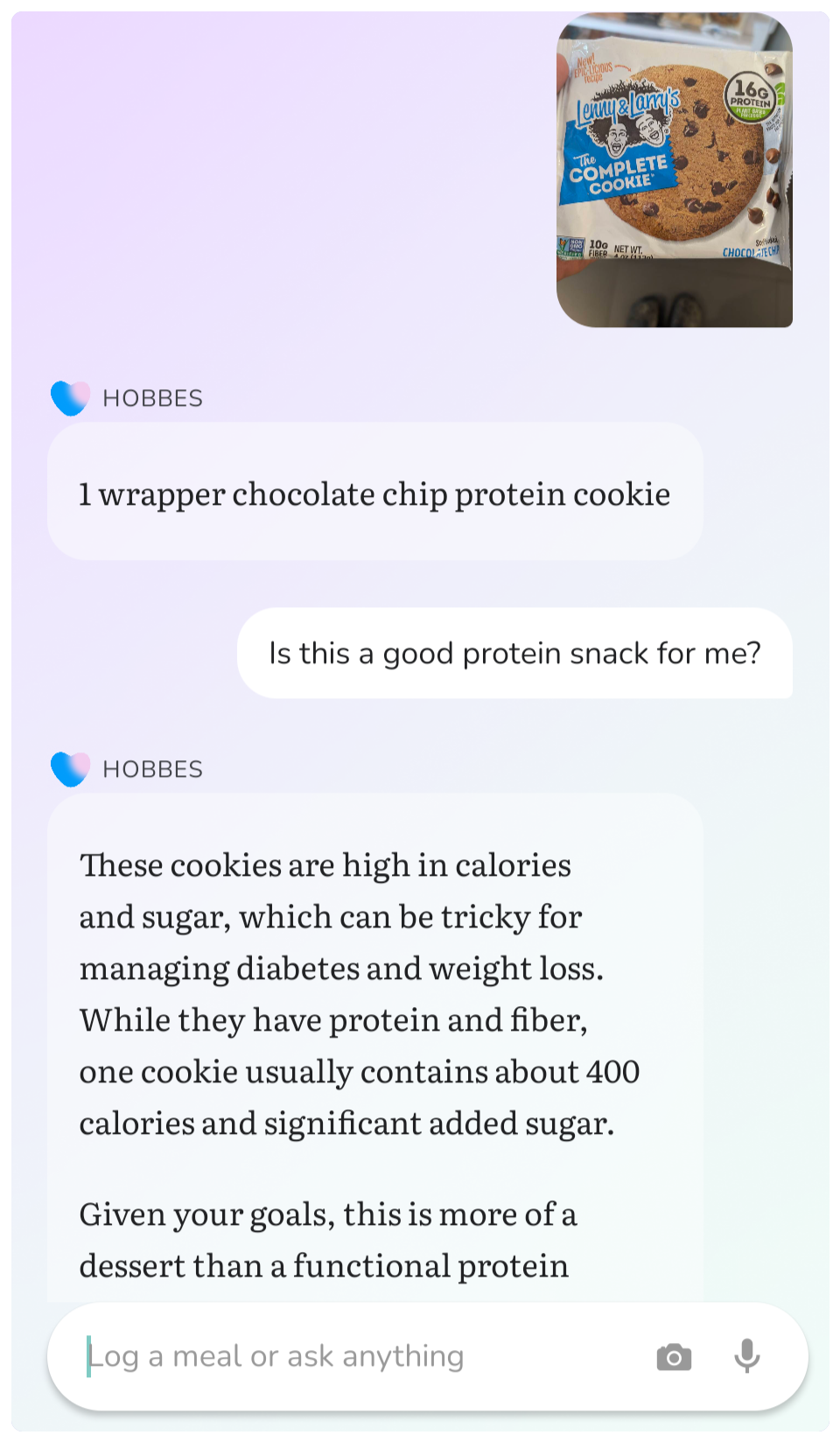
What I didn't anticipate was how often I'd use this as a coaching tool rather than just a logger. I'll snap a picture of something in the supermarket aisle and ask Hobbes whether it's a good choice for me. I get a personalized answer, drawing on what I've been eating and what my goals are. That feels like the beginning of what a good coach does.
Still early
None of this is perfect yet. But I can see it improving week over week, and I'm genuinely convinced we're building the best way to log meals, and, more importantly, the most useful coach built on top of that log.
Next post: plot twist. Hobbes isn't really about logging meals at all.